

The first time I used graphQL in a project wasn’t because of my sheer inquisition but because it was a requirement of the project. Though I had read articles about the benefits of gaphQL and had learned a bit about its mechanisms, I’ve never had undertaken any real implementations.
After a quick scan on the internet, we managed to create a basic graphQL setup using apollo-client on our react app, scaffolded with vite. The declarative data fetching, built-in caching, and the abundance of resources on the internet for apollo-client simplified the adoption of graphQL. It took us mere days to get used to all the hooks for queries and mutations. The experience was pretty smooth because frankly there’s not much to learn besides being able to write queries and mutations after having the setup for apollo-client. Over time, we started exploring caches and re-fetch policies and after things started getting a little complex, we looked into best practices in the industry.
We were using typescript with react so we had to create all the types for all the data to be sent and received. We needed to keep track of all the updates of queries and mutations and accordingly update all the typings to maintain a bug-free typed system. There were lots of repeated fields and for those, there were repeated typings. The operation names were being duplicated as there was no system to make them unique. The application got complex.
There, we realized our biggest mistake: We started using graphQL without proper research. We just learned the bare minimum required to get the project running but not enough to properly organize and structure the application.
Had we done our research a bit more intensely, we would have found some pretty good packages or concepts that could have simplified our code.
Fragments: You can implement graphQL and complete the project without even having to come across the concepts of fragments (we did). But you’ll have several repeated fields on your queries or mutations that start to make your application more complex and unstructured. Once we learned about these reusable units, called fragments, that graphQL provides it got a lot easier to keep track of changing APIs.
Automatic type generator: I’ve come to realize graphQL with typescript is one of the best combinations there is. Believe me, after all the hectic creation and updates of types for every query you get frustrated with maintaining the synced changes throughout the codebase. But later on, we found this beautiful tool that generates codes out of graphQL schema. I mean, how cool is that. Had we found these earlier, we would have saved half our development hours.
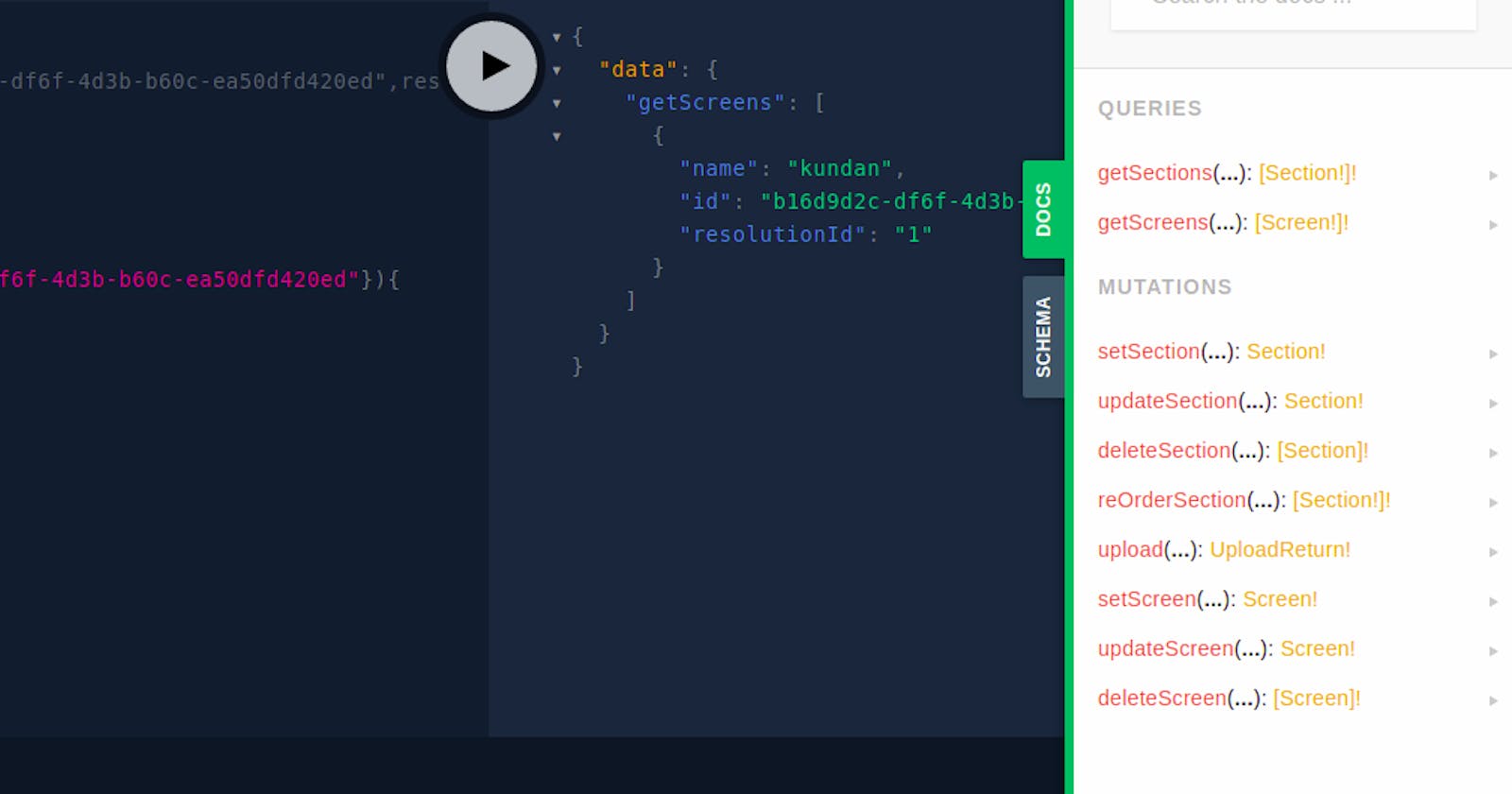
GraphQL is a beautiful query language for API. As it uses a type system to define the API, it becomes easier for you to understand what the result of the query will be. Besides, the playground that a graphQL service provides is just marvelous. This drastically reduced the repeated nagging to backend developers to ask for any changes because all the resources are already available and as a frontend dev all you need to do is query the field that you need.
And with all this knowledge and experience, we started another project, and this time we did a lot better.
Check out how the project was set up. Spoilers, We used react-query with typescript.